

Você está agora seguindo
Erro seguindo usuário.
Esse usuários não permite que o sigam.
Você já está seguindo esse usuário.
Seu plano permite apenas 0 seguidas. Aprimore-o aqui.
Deixou de seguir com sucesso
Ocorreu um erro ao deixar de seguir o usuário.
Você recomendou com sucesso
Ocorreu um erro ao recomendar o usuário.
Algo deu errado. Por favor, atualize a página e tente novamente.
E-mail verificado com sucesso


siedlce,
poland
Atualmente, está 11:23 AM aqui
Ingressou em julho 23, 2013
0 Recomendações
Patryk S.
@PatrykSkowron
3,2
3,2
100%
100%
siedlce,
poland
100%
Trabalhos Concluídos
100%
Dentro do Orçamento
100%
No Prazo
50%
Taxa de Recontratação
Deep Learning engineer with expertise in NLP
Contate Patryk S. sobre seu trabalho
Faça login para discutir quaisquer detalhes via chat.
Portfólio
Portfólio
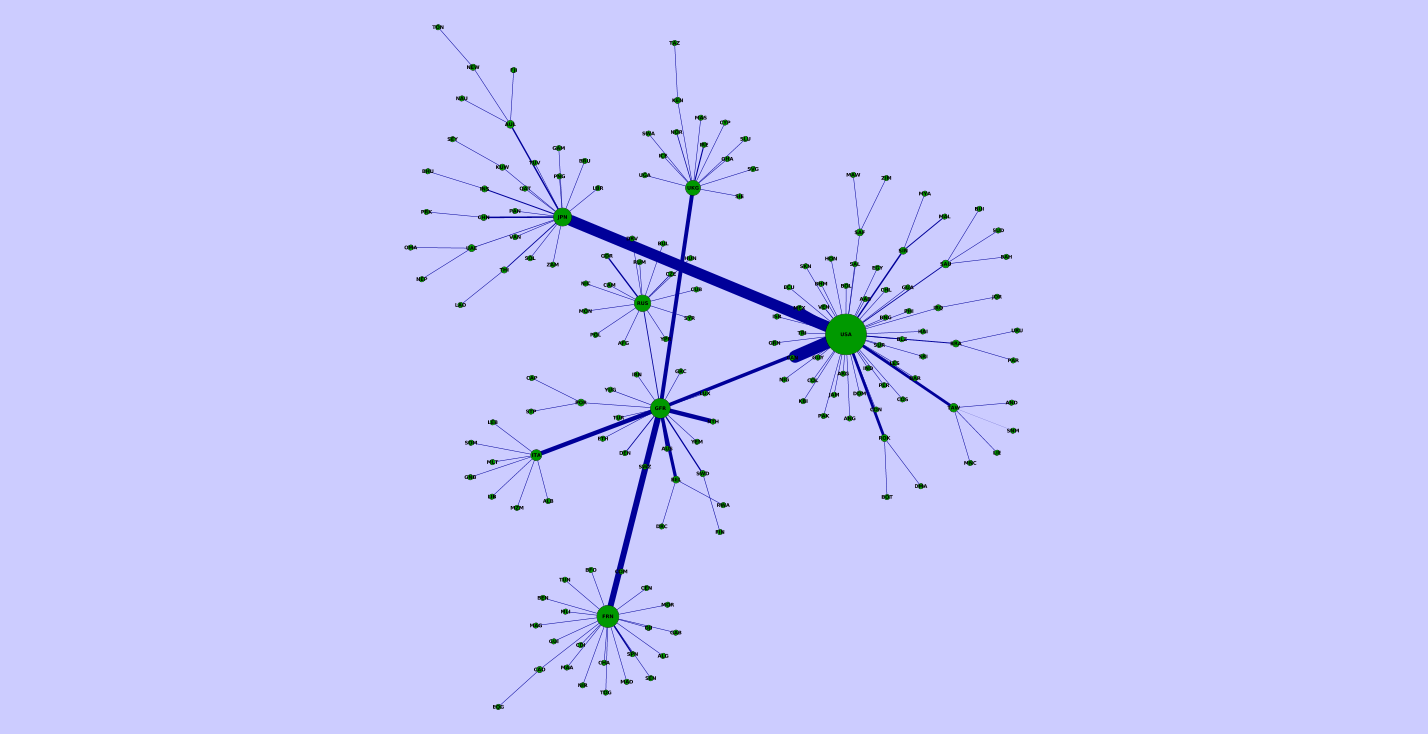

Minimum spanning tree of World Trade Web in 1989
Minimum spanning tree of World Trade Web in 1989
Avaliações
Mudanças salvas
Mostrando 1 - 5 de 6 avaliações
€50,00 EUR
R Programming Language

•
$50,00 USD
Data Processing
Matlab and Mathematica
Statistics
Mathematics

•
$70,00 USD
Matlab and Mathematica
Statistics
C++ Programming
Mathematics
•
$55,00 USD
Matlab and Mathematica
Statistics
C++ Programming
Mathematics
•
$50,00 USD
Matlab and Mathematica
Statistics
Mathematics
R Programming Language
•
Experiência
Natural Language Processing Engineer
jun. 2017 - Atual
During one year of work full of passion, I've learned how to obtain (crawling, scrapping, HTML extraction) big amount of data from various sources (web pages, JSONs, mongoDB), integrate them into datasets, train and evaluate machine learning models.
I am proficient in Python to write scripts and smaller systems that are optimized, highly readible and ready-to-reuse in other projects.
tools for ML: Tensorflow, Keras, Pandas, scikit-learn
Data Mining Specialist
set. 2015 - mai. 2017 (1 ano, 8 meses)
Writing advanced scripts in order to automate tasks (Python, SAS, SQL)
Participating in analytical projects for clients in telecom industry:
Building scoring models (e.g. churn / monetization models)
Streaming media industry:
Preparing customer behavioral segmentation models
Designing and Building 360 Degrees Data Mart
President and active member of academic organisation
out. 2010 - jun. 2015 (4 anos, 8 meses)
Organising work of the unit at Warsaw University of Technology as a president. Participating
and coordinating conferences, events, actions. Taking care of new members of association
as a head of human resources.
Educação
Master in Applied Physics (Complex systems modelling)
(1 ano)
Erasmus exchange (engineer studies)
(1 ano)
Engineer in Computational Physics
(4 anos)
Qualificações
Design Thinking Course
Design Thinking Warsaw organisation
2013
Completed course of Design Thinking - methodology for practical, creative resolution of problems or issues that looks for an improved future result.
Publicações
Master thesis: Crises modelling in the World Trade Web
Minimum spanning tree of World Trade Web
Warsaw University of Technology
In the paper analysis of undirected weighted graphs which represent
the world trade web in years 1950-2000 has been performed. Nodes indicate
countries. Edges represent trade connections between countries. To every edge
weight is assigned. This weight corresponds to trade volume. This analysis allows
one to identify the most important trade channels. In the paper this thesis is
confirmed. It was achieved using transformation of network to minimum spanning
tree which imitates its backbone. Firstly, ana
Contate Patryk S. sobre seu trabalho
Faça login para discutir quaisquer detalhes via chat.
Verificações
Principais Habilidades
Busque Freelancers Parecidos
Busque Mostruários Parecidos
Convite enviado com sucesso!
Obrigado! Te enviamos um link por e-mail para que você possa reivindicar seu crédito gratuito.
Algo deu errado ao enviar seu e-mail. Por favor, tente novamente.
Não foi possível copiar para a área de transferência, por favor, tente novamente após ajustar suas permissões.
Copiado para a área de transferência.
Carregando pré-visualização
Permissão concedida para Geolocalização.
Sua sessão expirou e você foi desconectado. Por favor, faça login novamente.