

Você está agora seguindo
Erro seguindo usuário.
Esse usuários não permite que o sigam.
Você já está seguindo esse usuário.
Seu plano permite apenas 0 seguidas. Aprimore-o aqui.
Deixou de seguir com sucesso
Ocorreu um erro ao deixar de seguir o usuário.
Você recomendou com sucesso
Ocorreu um erro ao recomendar o usuário.
Algo deu errado. Por favor, atualize a página e tente novamente.
E-mail verificado com sucesso

tashkent,
uzbekistan
Atualmente, está 7:17 AM aqui
Ingressou em novembro 27, 2021
1
Recomendação
Samidullo A.
@Samidullo
4,0
4,0
69%
69%
tashkent,
uzbekistan
100%
Trabalhos Concluídos
89%
Dentro do Orçamento
93%
No Prazo
5%
Taxa de Recontratação
Data scientist/ Data analytic / SQL / Tabeau
Contate Samidullo A. sobre seu trabalho
Faça login para discutir quaisquer detalhes via chat.
Portfólio
Portfólio


A5/1 Cryptography algorithm

A5/1 Cryptography algorithm


Data encryption standard (DES)

Data encryption standard (DES)
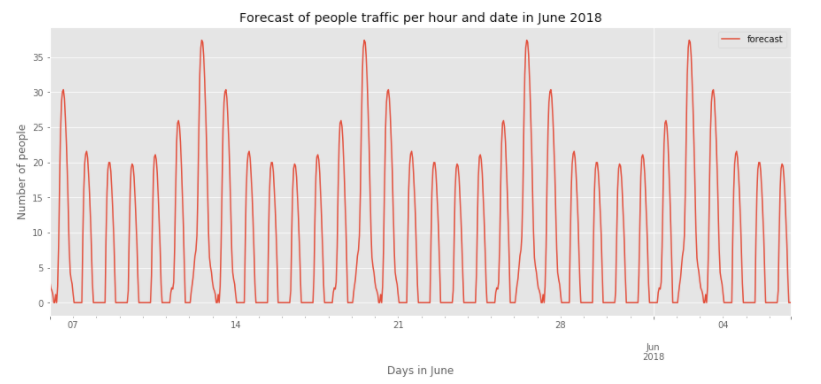

Traffic and Sales Analysis for US shop

Traffic and Sales Analysis for US shop

Traffic and Sales Analysis for US shop

Traffic and Sales Analysis for US shop


Decryption One-Time-Pad encrypted code without Passwork

Decryption One-Time-Pad encrypted code without Passwork

Decryption One-Time-Pad encrypted code without Passwork
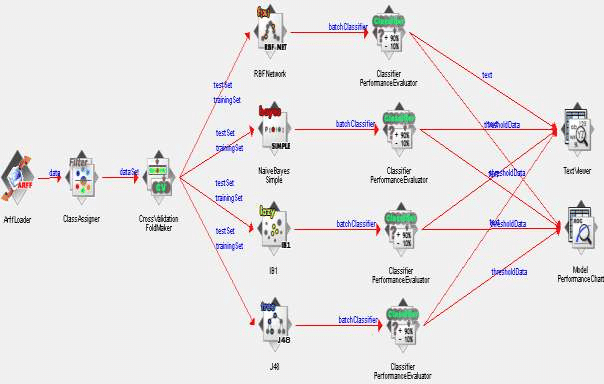

Using Weka knowledge flow
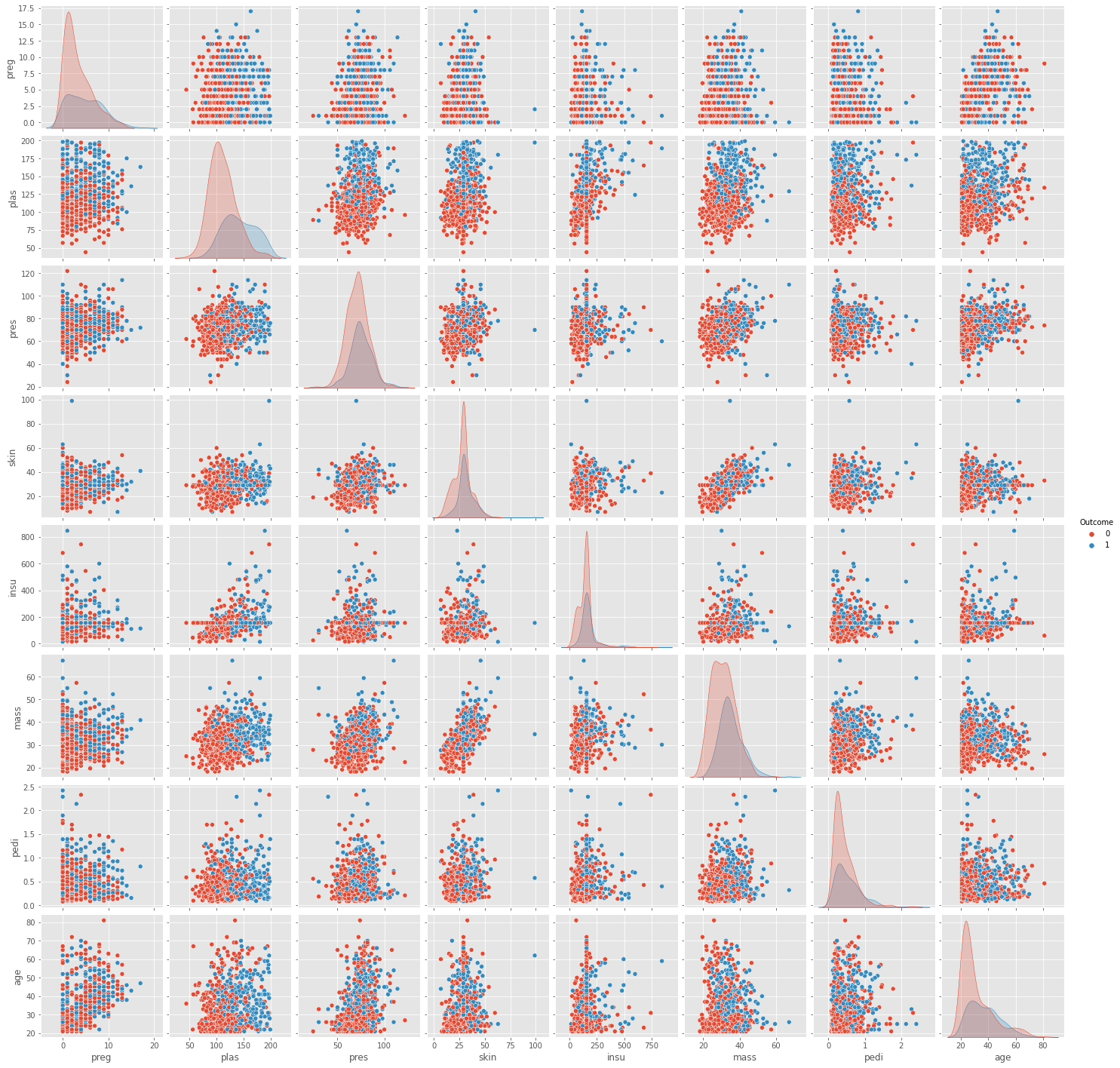

Unsupervised Kmeans algorithm used to clusted Iris data

Unsupervised Kmeans algorithm used to clusted Iris data

Unsupervised Kmeans algorithm used to clusted Iris data
A5/1 Cryptography algorithm
A5/1 Cryptography algorithm
Data encryption standard (DES)
Data encryption standard (DES)
Traffic and Sales Analysis for US shop
Traffic and Sales Analysis for US shop
Traffic and Sales Analysis for US shop
Traffic and Sales Analysis for US shop
Decryption One-Time-Pad encrypted code without Passwork
Decryption One-Time-Pad encrypted code without Passwork
Decryption One-Time-Pad encrypted code without Passwork
Using Weka knowledge flow
Unsupervised Kmeans algorithm used to clusted Iris data
Unsupervised Kmeans algorithm used to clusted Iris data
Unsupervised Kmeans algorithm used to clusted Iris data
Avaliações
Mudanças salvas
Mostrando 1 - 5 de 11 avaliações
£80,00 GBP
Data Processing
Excel
Data Mining
Data Analytics
Data Cleansing
A

•
₹2.000,00 INR
Python
Software Architecture
Statistics
Machine Learning (ML)
H

•
₹1.500,00 INR
Matlab and Mathematica
Mathematics
Linear Programming
MATLAB
+1 mais
V

•
$75,00 USD
Django
Data Visualization
Data Architecture
Computer Vision
+1 mais

•
₹23.150,00 INR
Python
Software Architecture
V
•
Qualificações
AI engineering
IBM
2021
About this Course
This course dives into the basics of machine learning using an approachable, and well-known programming language, Python.
In this course, we will be reviewing two main components:
First, you will be learning about the purpose of Machine Learning and where it applies to the real world.
Second, you will get a general overview of Machine Learning topics such as supervised vs unsupervised learning, model evaluation, and Machine Learning algorithms.
Contate Samidullo A. sobre seu trabalho
Faça login para discutir quaisquer detalhes via chat.
Verificações
Certificações
Principais Habilidades
Busque Freelancers Parecidos
Busque Mostruários Parecidos
Convite enviado com sucesso!
Obrigado! Te enviamos um link por e-mail para que você possa reivindicar seu crédito gratuito.
Algo deu errado ao enviar seu e-mail. Por favor, tente novamente.
Não foi possível copiar para a área de transferência, por favor, tente novamente após ajustar suas permissões.
Copiado para a área de transferência.
Carregando pré-visualização
Permissão concedida para Geolocalização.
Sua sessão expirou e você foi desconectado. Por favor, faça login novamente.